In the previous post we talked about the basic terminologies of kafka. One important term we defined was groupid which allows one consumer within the consumer group to consume the event.
Use case of groupId concept : In real world applications we have consumer running on multiple machines (maybe even in mutiple threads) subscribed to the same topic and each machine is running the same application logic or code to consume and process the event ; but we would want the event to be consumed and processed on same machine i.e only once and not by every consumer of every machine. This can simply be achieved by assigning the same groupId to all the consumers of that topic.
Example : Let's say the myFood Matching application has the logic to make a call to tracking delivery boy application and to make some entry for the response in some database.
If you don't assign the groupid all the consumers(machines) would consumer the same event and make calls and multiple entry in db.
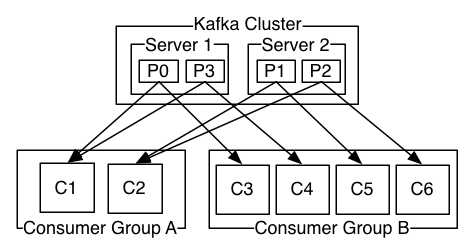
Kafka evenly distributes the partitions of the topic amongst the consumers of the same consumer group as shown above.
This is typically how you assign the groupid property to the consumer and create a consumer
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s", record.offset(), record.key(), record.value());
}
Parallelism in kafka using multiple partitions: Parallelism can be achieved to max extent by increasing the number of partitions to the number of machines ; since each consumer/machine will be assigned a particular partition by kafka. So if you have 4 partitions of a topic and 4 consumers (1 on each machine) with same groupId all the events/messages will be equally distributed. On the contrary if you have 4 consumers but only 2 partitions , 2 consumers will not be utilised.
Terminal command to create topic with 4 partitions:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 4 --topic foo
Terminal command to alter topic
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic topic1 --partitions 4
Partitioning in kafka: Partitioning in kafka provides a logic on the basis of which producer can control that an event with a particular key must always go to a designated partition.
Use case: Let's say you have to aggregate the events of "order" topic to count the number of orders for a particular restaurant for 1 minute to perform better matching with the delivery boy.
Let's say the order event looks like this:(skipping other fields for simplicity)
orderId: long
restaurantId : long
dishId: long
customerId:long
paymentMode:string
Note that the key to aggregate the count of events here is restaurantId for our problem statement.
How will I do it? Major problem here is that any event can be pushed to any partition and hence be consumed by any consumer (or any machine) so i can't store the count for sure in local cache.
Another approach would be to store the count in some sql/no sql Db with locking mechanism.
Again problem here is even row wise locking is an expensive and time consuming operation.
Here is how I would solve this problem:
Use kafka partitioning concept to push the events with a particular key to a designated partition that means the event with the same restaurant Id will always be consumed by the same machine/consumer allowing me to update in db without acquiring any lock.
Local cache can also be used to aggregate the count for a fixed interval and then flush in db.
Partition can simply be calculated as below and pugged in to the send method of kafka producer:
partition = event.restaurantId % no_of_partitions
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1) , callback);
Hope you liked this informative article! If any questions please add a comment below.
Also share if you have any other way to approach the problem statements discussed in the post.
In the next post I will share a cheat sheet for all the frequently used kafka terminal commands.





Comments
Post a Comment